Un estudio realizado por el Columbia Journalism Review ha resaltado los problemas que tienen las IA para reconocer la fiabilidad de sus respuestas y citar las fuentes de información. Este problema resulta significativo cuando se considera que en Estados Unidos el 25% de la población utiliza a los modelos como alternativas a los motores de búsqueda.
El trabajo estuvo enfocado en el área de las noticias, pero los investigadores advierten que la confiabilidad de las respuestas en otros aspectos también ha quedado en duda.
Nivel de error
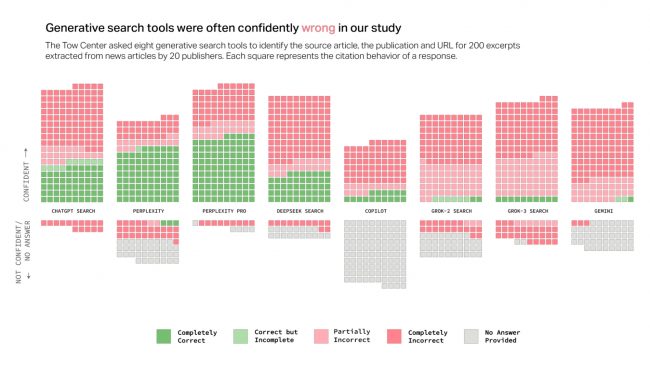
Los errores varían de un modelo a otro. Algunos de los casos más serios son el de ChatGPT, que en el estudio falló en el 67% de las consultas. Grok 3 lo hizo aún peor, llegó a un 94% de error. Una de las que mejor se desempeñó fue Perplexity, con un 37%, que sigue siendo una proporción elevadísima.
Los problemas de las IA
En términos generales la investigación ha mostrado que los sistemas tienen problemas para rechazar las preguntas que no pueden responder de forma precisa. En cambio, a menudo responden de forma incorrecta e incluso realizan especulaciones. Esto no ocurrió en un solo modelo, es un comportamiento común.
Las versiones premium de los chatbots pueden ser algo más precisas, pero también demostraron tener mayor confianza cuando respondieron de forma incorrecta. Es más difícil que admitan no saber sobre un tema y por tanto producen más errores.
Los enlaces provistos como referencias no son confiables. Y en mucho casos en los que se citaba una fuente, esta no era la original. Los acuerdos establecidos con las fuentes de información, como ocurre con algunas desarrolladoras y editoriales, no parecen haber mejorado mucho la citación de fuentes.
Por otro lado, las IA suelen ignorar los protocolos de exclusión de los sitios web que las editoriales emplean para indicar que no quieren que su contenido sea recopilado para entrenamiento. En el caso de Perplexity carios artículos de acceso pago fueron citados. A pesar de que las editoriales habían señalado específicamente que no querían participar en la recolección de datos de este sistema.